Android, Kotlin Flow во ViewModel - все сложно.
Перевод статьи Kotlin’s Flow in ViewModels: it’s complicated.
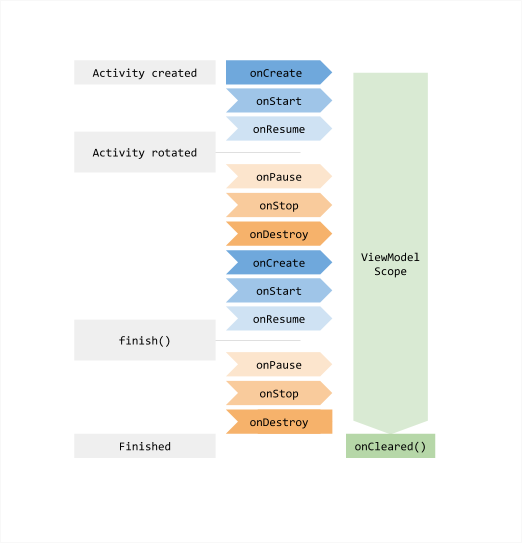
Загрузка данных для UI в приложении Android может быть непростой задачей. Нам надо учитывать жизненный цикл компонентов Android и изменения конфигурации, потому что все это приводит к уничтожению и восстановлению Activity.
Отдельные экраны приложения постоянно переключаются между активным и неактивным состоянием, когда пользователь ходит вперед назад по экранам, переключается с одного приложения на другое, блокирует и разблокирует экран. Каждый компонент должен выполнять активную работу в нужном состоянии экрана.
Изменения конфигурации происходят в случаях:
- при изменении ориентации экрана;
- когда приложение переключается в мульти-оконный режим;
- при переключении визуальной темы смартфона;
- при изменении системных настроек - языка, шрифтов и т.д.
Повышаем эффективность
Для улучшения пользовательского опыта, эффективная загрузка данных во Fragment и Activity должна учитывать следующие правила:
-
Кеширование: актуальные загруженные данные, должны быть доставлены немедленно и не загружаться повторно. В частности, когда существующий Fragment или Activity становятся видимыми снова или Activity пересоздается после изменения конфигурации.
-
Избегать фоновую работу: когда Activity или Fragment скрываются (состояние изменяется со
STARTEDнаSTOPPED), любая работа по загрузке внешних данных должна вставать на паузу или отменяться для экономии ресурсов. Это особенно важно для бесконeчных потоков данных, как например геолокация или периодическое обновление каких-либо данных. -
Работа не прерывается при изменении конфигурации: это исключение из правила #2, Во время смены конфигурации, текущая Activity заменяется новым экземпляром с сохранением состояния, поэтому отменять текущую работу в старом экземпляре Activity и перезапускать работу при создании нового экземпляра Activiti было бы контр продуктивно.
Современный подход: ViewModel и LiveData
В 2017 Google зарелизила первый набор библиотек Architecture Components, там появились ViewModel и LiveData компоненты, которые помогают разработчикам эффективно работать с данными, поддерживая все 3 правила выше.
ViewModel, сохраняет данные при изменении конфигурации, используется для достижения правил #1 и #3: операции загрузки выполняются непрерывно во время изменения конфигурации, полученные данные могут кешироваться и совместно использоваться одним, или несколькими Fragment или Activity.
LiveData, простой контейнер данных, поддерживающий подписку на изменения и учитывающий жизненный цикл компонентов Android. Новые данные отправляются наблюдателям только когда их жизненный цикл в состоянии не менее STARTED (видимый), наблюдатели отписываются автоматически, что избавляет от утечек памяти. LiveData используется для достижения правил #1 и #2: кеширует последнее значение данных и это значение автоматически отправляется новым наблюдателям. В дополнение, LiveData уведомляет, когда в состоянии STARTED больше нет наблюдателей и можно избежать ненужной фоновой работы.
Опытный разработчик, как правило уже знаком со всем этим. Но важно вспомнить все возможности, чтобы сравнить их с Flow.
LiveData + Coroutines
LiveData довольна ограничена по сравнению с реактивными решениями (например RxJava):
- передает и берет данные только на главном потоке (main thread). Интересно, что оператор
mapвыполняет трансформацию объектов на главном потоке и не может использоваться на I/O потоках или для тяжелых вычислений на CPU. Для этого используется операторswitchMapсовместно с ручным запуском асинхронной операции в нужном потоке, даже если в основной поток надо отправить единственное значение. - есть только 3 оператора преобразования для LiveData:
map(),switchMap()иdistinctUntilChanged(). Если вам нужно больше, вы должны сами это сделать, используяMediatorLiveData.
Чтобы преодолеть эти ограничения, библиотеки Jetpack дают специальные “мосты” из LiveData для других технологий, таких как RxJava или Kotlin корутины.
Самый простой и наиболее элегантный из них, по мнению автора, это LiveData coroutine builder, подключается через androidx.lifecycle:lifecycle-livedata-ktx Gradle зависимость. Этот функционал похож на flow {} builder function из библиотеки Kotlin Coroutines и позволяет грамотно обернуть корутину в экземпляр LiveData:
val result: LiveData<Result> = liveData {
val data = someSuspendingFunction()
emit(data)
}
- Вы можете использовать все силу корутин, их контекстов для написания асинхронного кода в синхронной манере без колбеков, автоматически переключаясь между нужными потоками;
- Новые значения отправляются наблюдателям LiveData в главном потоке через suspending методы
emit()илиemitSource()из корутины; - Корутина использует специальную область видимости (scope) и жизненный цикл привязанный к экземпляру LiveData. Когда LiveData становится неактивной (это значит, что больше нет наблюдателей в состоянии
STARTED), то корутина будет автоматически отменена, работает правило #2; - В реальности отмена корутины будет задержана на 5 секунд после того как LiveData станет неактивной для правильной обработки смены конфигурации: если новая Activity немедленно заменит старую и LiveData станет активной до срабатывания задержки, то отмена корутины не будет и цена перезапуска будет нулевой (правило #3);
- если пользователь вернется назад на экран и LiveData станет активной, то корутина автоматически перезапустится, но только если она была отменена до завершения. Как только корутина завершится, она больше не будет перезапускаться, те же данные не будут загружаться дважды, если входные параметры не изменились (правило #1).
Вывод: используйте LiveData coroutines builder, это дает простой код и лучшее поведение по умолчанию.
А что если, репозиторий возвращает поток значений в форме Flow (вместо suspend функций с единственным значением)? В этом случае также возможно сконвертировать поток в LiveData и использовать все преимущества перечисленные выше, используя asLiveData() функцию-расширение.
val result: LiveData<Result> = someFunctionReturningFlow().asLiveData()
Внутри asLiveData() также использует LiveData coroutines builder для создания простой корутины обрабатывающий Flow пока LiveData активна:
fun <T> Flow<T>.asLiveData(): LiveData<T> = liveData {
collect {
emit(it)
}
}
Но давайте остановимся ненадолго – что такое Flow и можно ли им полностью заменить LiveData?
Введение в Kotlin Flow

Flow это класс из библиотеки Kotlin Coroutines представленной в 2019 году, класс является потоком значений, вычисляемый асинхронно. Концептуально похож на RxJava Observable, но основан на корутинах и имеет более простой API.
Изначально были доступны только холодные потоки (cold flows): потоки без состояний, которые создаются по требованию каждый раз, когда наблюдатель начинает собирать значения в области видимости (scope) корутины. Каждый наблюдатель получает собственную последовательность значений, они не общие.
Позже были добавлены новые горячие потоки подтипы Flow: SharedFlow и StateFlow. Они были выпущены со стабильной реализацией API в версии библиотеки корутин #1.4.0.
SharedFlow публикует данные, которые распространяются всем слушателям. Класс может управлять дополнительным кешем и/или буфером и фактически заменяет все варианты устаревшего BroadcastChannel API.
StateFlow специально оптимизированный подкласс SharedFlow, который хранит и воспроизводит только последнее значение. Что-то знакомое, да?
StateFlow и LiveData много общего:
- Эти классы наблюдаемые (observable)
- Они хранят и распространяют последнее значение любому количеству наблюдателей
- Они заставляют перехватывать ошибки на ранней стадии: необработанное исключение (
Exception) в колбеке LiveData останавливает приложение. Не пойманное исключение в горячем Flow потоке завершает поток без возможности перезапустить его, даже если использовать оператор.catch().
Но есть и важные отличия:
MutableStateFlowтребует начального значения, в отличие отMutableLiveData. Замечание:MutableSharedFlow(replay = 1)может эмулироватьMutableStateFlowбез начального значения, но данная реализация менее эффективна.StateFlowвсегда фильтрует повторяющиеся значения с помощью сравненияAny.equals(),LiveDataтак не делает, для этого следует подключить операторdistinctUntilChanged()(замечание:SharedFlowне имеет такого поведения).StateFlowне учитывает жизненный цикл (not lifecycle-aware). Однако,Flowможет быть использовано в корутине с учетом жизненного цикла, это требует некоторого кода для настройки без использования LiveData (детали ниже).LiveDataиспользует “версионность”, чтобы управлять отправкой значений наблюдателям. При помощи этого наблюдатель не получит дважды одного и того же значения при переходе обратно в состояниеSTARTED.StateFlowне использует “версионность”. Каждый раз, когда корутина собирает данныеFlow, она рассматривается как новый наблюдатель и всегда будет получать сначала последнее значение. Из-за этого может быть дублирование работы, как мы увидим на следующем примере.
Наблюдение за LiveData против сбора данных в Flow
Организовать наблюдение за экземпляром LiveData довольно просто:
viewModel.results.observe(viewLifecycleOwner) { data ->
displayResult(data)
}
Эта операция однократная и дальше LiveData берет на себя синхронизацию потока данных с жизненным циклом наблюдателей.
Аналогичная операция для Flow называется сбором (collecting) и сбор должен выполняться в корутине. Из-за того, что Flow не знает ничего о жизненном цикле, ответственность за жизненный цикл возлагают на корутину, работающую с Flow.
Чтобы создать корутину для работы с Flow, учитывающую жизненный цикл Activity/Fragment (запускать работу с данными при состоянии STARTED и автоматически отменять эту работу при уничтожении):
viewLifecycleOwner.lifecycleScope.launchWhenStarted {
viewModel.result.collect { data ->
displayResult(data)
}
}
Но здесь есть серьезное ограничение: код будет работать правильно только с “холодными” потоками, без поддержки каналом или буфером. Такой Flow управляется только собирающей его корутиной: когда Activity/Fragment перейдет в состояние STOPPPED, корутина приостановится, производитель Flow также приостановится с ней, и больше ничего не произойдет пока корутина не возобновится.
Однако, есть и другие виды Flow:
- горячие потоки, которые всегда активные и посылают результаты всем текущим наблюдателями (включая приостановленные);
- холодные потоки с колбэком или поддержкой канала, которые подписываются на активный источник данных, когда сбор данных запускается и останавливает подписку, когда сбор данных отменяется (не приостанавливается).
В этих случаях, основной производитель Flow будет оставаться активным даже когда корутина будет приостановлена, сохраняя (в буфер) новые результаты в фоновом режиме. Ресурсы расходуются впустую, правило #2 нарушается.

Нужно создать более безопасный способ сборка Flow любого типа. Корутина работающая с потоком данных, должна быть отменена когда Activity/Fragment становится невидимой и перезапущена снова, так же как это делает LiveData-Coroutine-Builder. Для этого был представлен новый API в lifecycle:lifecycle-runtime-ktx:2.4.0 (остается в статусе alpha на момент написания статьи, на момент перевода - перешел в beta).
viewLifecycleOwner.lifecycleScope.launch {
viewLifecycleOwner.repeatOnLifecycle(Lifecycle.State.STARTED) {
viewModel.result.collect { data ->
displayResult(data)
}
}
}
Или аналогично:
viewLifecycleOwner.lifecycleScope.launch {
viewModel.result
.flowWithLifecycle(viewLifecycleOwner.lifecycle, Lifecycle.State.STARTED)
.collect { data ->
displayResult(data)
}
}
Как видно, эффективно и безопасно работать с данными в Actvivity или Fragment проще с помощью LiveData.
Можно посмотреть дополнительную информацию о новом API в статье “A safer way to collect flows from Android UIs. from Manuel Vivo.
Заменяем LiveData на StateFlow во ViewModel
Давайте-ка вернемся к ViewModel. Мы убедились, что это простой и эффективный способ работы с данными в асинхронном режиме:
val result: LiveData<Result> = liveData {
val data = someSuspendingFunction()
emit(data)
}
Как мы можем добиться того же самого, используя StateFlow вместо LiveData? Jose Alcérreca написал внушительное руководство для ответа на этот вопрос. Вкратце, для случая выше, код будет выглядеть так:
val result: Flow<Result> = flow {
val data = someSuspendingFunction()
emit(data)
}.stateIn(
scope = viewModelScope,
started = SharingStarted.WhileSubscribed(5000L),
initialValue = Result.Loading
)
Оператор stateIn() трансформирует наш холодный Flow в горячий, способный делиться одним и тем же результатом между разными наблюдателями. Благодаря SharingStarted.WhileSubscribed(5000L), горячий поток запускается лениво при подписке первого наблюдателя и отменяется через 5 секунд, когда последний наблюдатель отпишется, что позволяет избегать лишней работы в фоновом режиме и при этом сохраняется работа при смене конфигурации. Кроме того, как только исходящий поток данных достигнет конца, он не будет перезапущен автоматически, этим мы избегаем двойной работы.
Похоже, что мы сумели выполнить 3 наших правила и воспроизвести почти такое же поведение как у LiveData с использованием более сложного кода.
Все же еще остается небольшая, но важная разница: каждый раз когда Activity/Fragment становится видимым снова, начинается новый сбор потока и StateFlow всегда будет отправлять последний результат наблюдателю немедленно. Даже если этот же результат был уже доставлен в тот же самый Activity/Fragment во время последнего сбора данных. Потому что StateFlow не поддерживает версионность (в отличие от LiveData) и каждый новый сбор потока данных - это новый подписчик.
Это проблематично? Для простых случаев нет, Activity или Fragment могут сделать дополнительную проверку, чтобы не делать лишнее обновление UI, если данные не изменились.
viewLifecycleOwner.lifecycleScope.launch {
viewModel.result
.flowWithLifecycle(viewLifecycleOwner.lifecycle, Lifecycle.State.STARTED)
.distinctUntilChanged()
.collect { data ->
displayResult(data)
}
}
Проблемы возникают в более сложных, реальных случаях, как мы увидим в следующем разделе.
Использование StateFlow как триггер во ViewModel
Подход на основе триггера обычно используется во ViewModel: каждый раз когда значение триггера изменяется - данные обновляются.
MutableLiveData для этого работает очень хорошо:
class MyViewModel(repository: MyRepository) : ViewModel() {
private val trigger = MutableLiveData<String>()
fun setQuery(query: String) {
trigger.value = query
}
val results: LiveData<SearchResult>
= trigger.switchMap { query ->
liveData {
emit(repository.search(query))
}
}
}
-
При обновлении, оператор
switchMap()подключает наблюдателей к новому источнику LiveData, заменяя старый. И так как в примере выше, используется LiveData coroutine builder, старая LiveData автоматически отменит связанную с ним корутину через 5 секунд после отключения от своих наблюдателей. Работа с устаревшими данными прекращается с небольшой задержкой. -
Так как в LiveData есть версионность,
MutableLiveDataтриггер отправит новое значение только один раз операторуswitchMap(), как только появится хотя бы один активный наблюдатель. Позже, если наблюдатели становятся неактивными и активными снова, работа источника данных LiveData просто возобновится с последними данными, где она остановилась.
Этот код достаточно прост и соблюдает все правила по эффективности выше.
Давайте посмотрим, можно ли реализовать ту же самую логику с классом MutableStateFlow вместо MutableLiveData.
Наивный подход
class MyViewModel(repository: MyRepository) : ViewModel() {
private val trigger = MutableStateFlow("")
fun setQuery(query: String) {
trigger.value = query
}
val results: Flow<SearchResult> = trigger.mapLatest { query ->
repository.search(query)
}.stateIn(
scope = viewModelScope,
started = SharingStarted.WhileSubscribed(5000L),
initialValue = SearchResult.EMPTY
)
}
API MutableLiveData и MutableLiveData выглядят очень похоже, код триггера выглядит почти одинаково. Самое большое различие это использование mapLatest, это эквивалент функции switchMap() в LiveData для возвращения единственного значения (для возвращения нескольких значений, надо использовать flatMapLatest).
mapLatest() работает как map(), но вместо полного преобразования по порядку всех входных значений, входные значения используются немедленно, а преобразование происходит в отдельной корутине асинхронно. При появлении нового значения во входящем потоке данных, трансформация предыдущего значения будет немедленно отменена, если она все еще работала и вместо нее будет запущена новая трансформация. Таким образом можно избежать работы с устаревшими данными.
Вроде выглядит неплохо. Однако здесь всплывает основная проблема: так как StateFlow не поддерживает версионность, триггер отправит повторно последнее значение, когда Flow перезапустится. Это случается каждый раз, когда Activity/Frgament становится видимым опять, после того, как был невидимым более 5 секунд.

Триггер выдает значение повторно, mapLatest() снова запускается, еще раз дергается метод в репозитории с теми же аргументами, хотя результат уже был получен и обработан.
Правило #1 не работает: актуальные данные не должны загружаться повторно.
Чиним повторную отправку последнего сообщения
Вопросы приходящие на ум: должны ли мы предотвращать повторную отправку и как это сделать? StateFlow уже позаботился об этом внутри коллекции flow и оператор distinctUntilChanged() делает то же самое для других типов flow. При этом нет стандартного оператора для отмены повторной отправки среди множества коллекций одного и того же flow, потому что flow коллекции должны быть самодостаточные. Это главная разница с LiveData.
В конкретном случае flow разделяемого между несколькими наблюдателями с использованием оператора stateIn(), исходящие значения будут кешироваться и в любой момент времени будет только одна корутина обрабатывающая эти значения. Можно попробовать взломать какой-нибудь оператор, который будет запоминать последнее значение предыдущей коллекции, чтобы пропустить его, когда запускается новая коллекция (не делайте так на работе, да и дома тоже):
// Don't do this at home (or at work)
fun <T> Flow<T>.rememberLatest(): Flow<T> {
var latest: Any? = NULL
return flow {
collectIndexed { index, value ->
if (index != 0 || value !== latest) {
emit(value)
latest = value
}
}
}
}
Примечание: внимательный читатель может заметить, что такое же поведение достигается за счет замены
MutableStateFlowсChannel(capacity = CONFLATED)и затем превратиь его в Flow с использованиемreceiveAsFlow(). Сhannel никогда не передают значение повторно.
К сожалению, логика в коде выше несовершенна и перестанет работать, как задумано, когда трансформация flow будет отменена до завершения.
Код предполагает, что после возврата emit(value), значение было обработано и не должно быть выдано снова, если сбор flow перезапустится, но это так, только при использовании не буферизированных Flow операторов. Операторы, подобные mapLatest(), буферизированные и в этом случае emit(value) вернется немедленно, при этом преобразование выполняется асинхронно. Это значит, что нет способа узнать, когда значение было обработано flow. Если сбор flow отменяется в середине асинхронного преобразования, нам все равно придется повторно сделать emit последнего значения, когда сбор flow возобновится, чтобы возобновить преобразование, иначе значение будет потеряно.
TL;DR Использование
StateFlowв качестве триггера в ViewModel приводит к дублирующейся работе каждый раз когда Activity/Fragment становится видимой повторно и здесь нет простого пути избежать такого поведения.
Вот почему LiveData предпочтительнее StateFlow при использовании как триггер во ViewModel. Эти различия не упоминаются в Codelab от Google - Advanced coroutines with Kotlin Flow, там подразумевается, что реализация на Flow ведет себя так же как на LiveData. Но это не так.
Выводы
Мои рекомендации на основании примеров выше:
- Продолжайте использовать LiveData в вашем Android-UI слое и ViewModels, особенно в качестве триггера. Используйте это везде, для передачи данных в Activity/Fragment: код будет простым и эффективным;
- LiveData coroutine builder ваш друг и может заменить Flows во ViewModels в большинстве случаев;
- Вы можете использовать мощь Flow операторов при необходимости, конвертируя Flows в LiveData;
- Flow лучше подходит, чем LiveData, для других слоев приложения, таких как - репозитории, источники данных и т.д., они не завязаны на платформенные особенности Android и их будет легче тестировать.
Теперь вы знаете все компромиcсы при переходе от LiveData к подходу “полностью на Flow” в вашем Android-UI слое.